一致性Hash算法
需求
在使用n台缓存服务器时,一种常见的负载均衡的做法是:对资源o的请求做hash(o) mod n,来决定映射的到的服务器。当需要增加或减少缓存服务器时,最糟糕的情况是,因为所有hash(o) mod n值被改变,导致所有缓存失效。
一致性哈希要求在服务器数量变化时,也尽量使同一个资源的请求,落在同一台服务器上。
原理
一致性哈希采用环状结构,先给每个节点(集群)计算Hash,并且将节点根据Hash值放在环中指定位置,然后对资源请求做Hash,沿着顺时针的方向找到环上满足条件的第一个节点,就是该请求对应的节点。
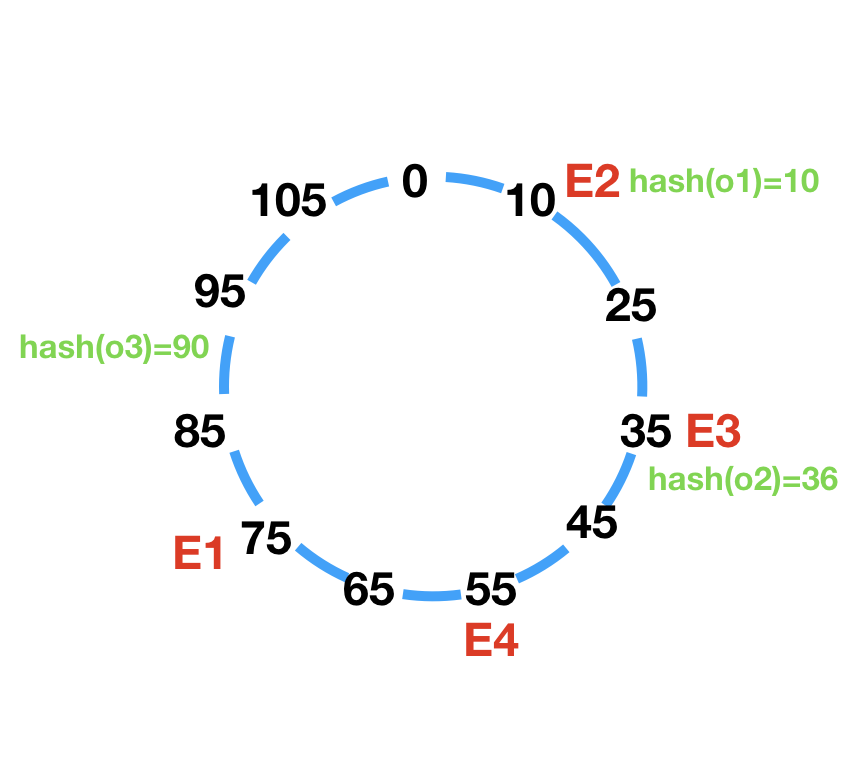
例如有如下哈希环,每个数字代表一个哈希值:
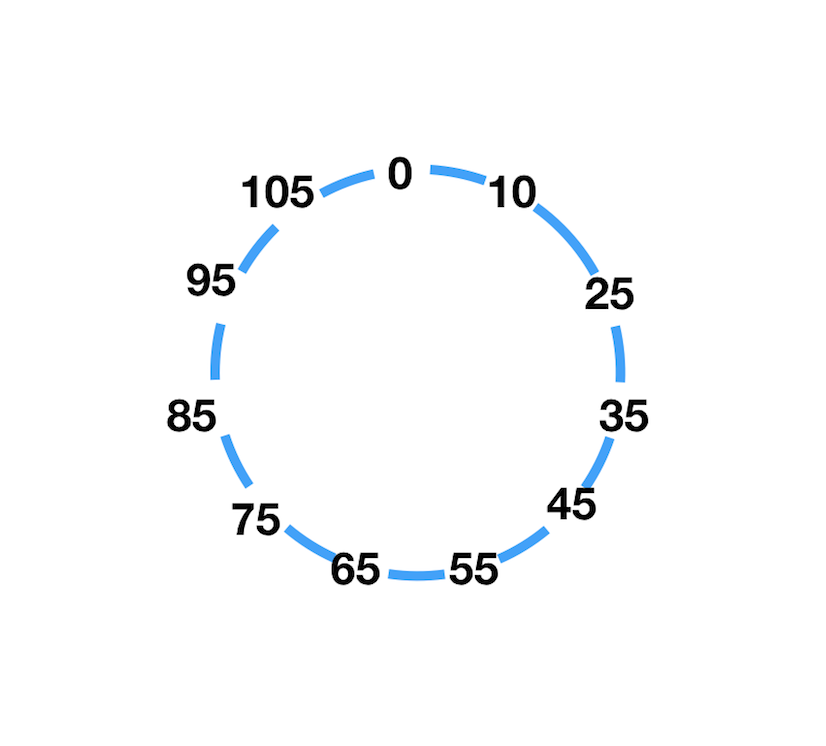
有3台缓存服务器(E1~E3),哈希值为hash(E1)=75,hash(E2)=10,hash(E3)=35,将3个节点放入环中:
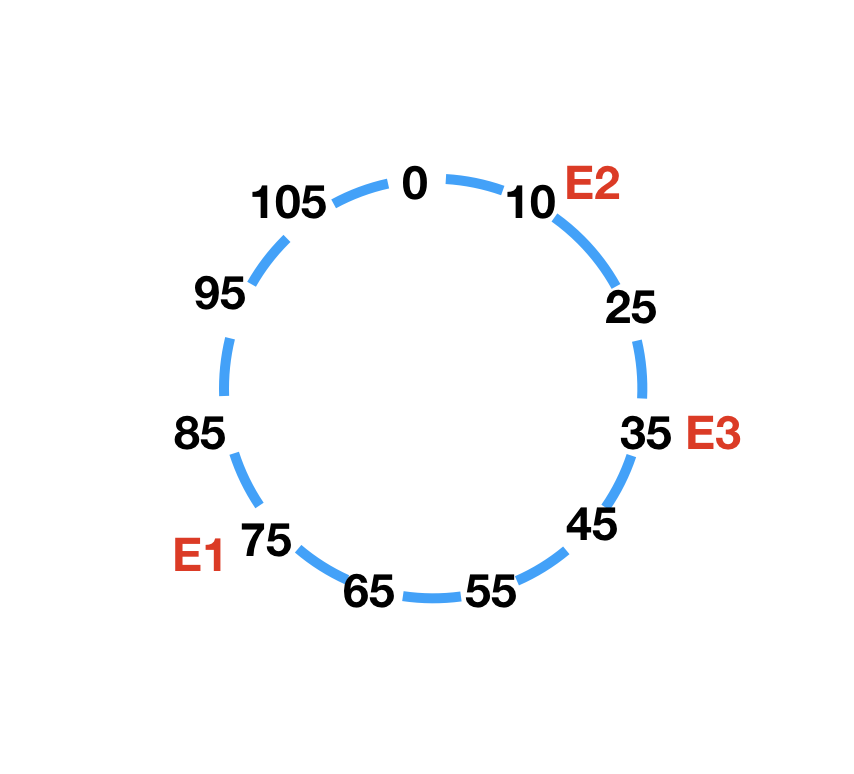
资源请求(o1~o3),哈希值为hash(o1)=10,hash(o2)=36,hash(o3)=90,将3个请求放入环中:
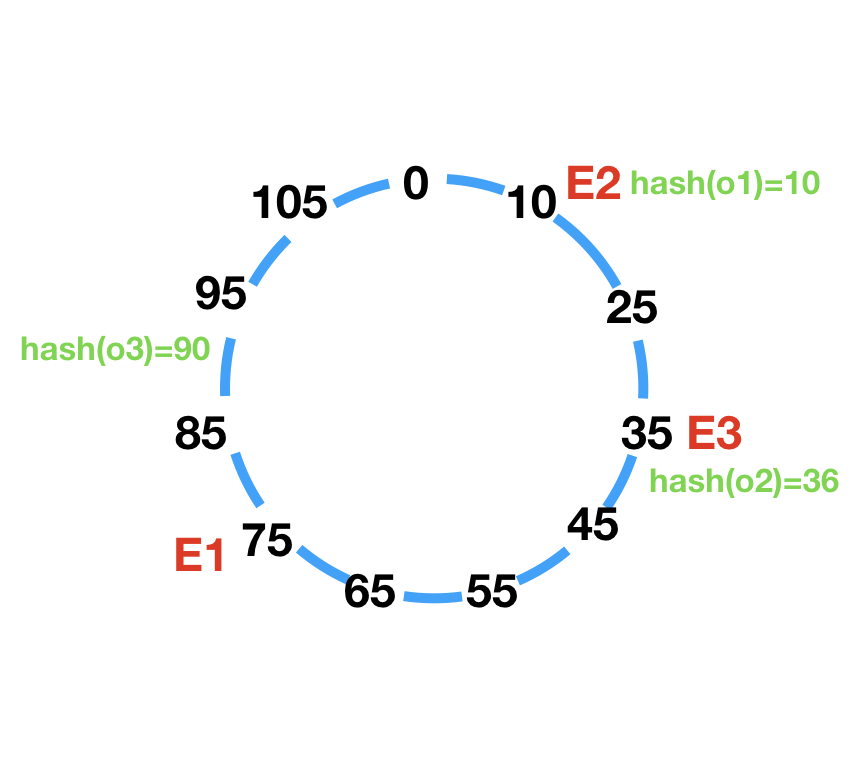
然后顺时针找到第一个节点,可以得出o1请求到E2,o2请求到E1,o3请求到E2。
1.此时如果删除E1,受影响的只有请求o2,从请求节点E1转移到E2:
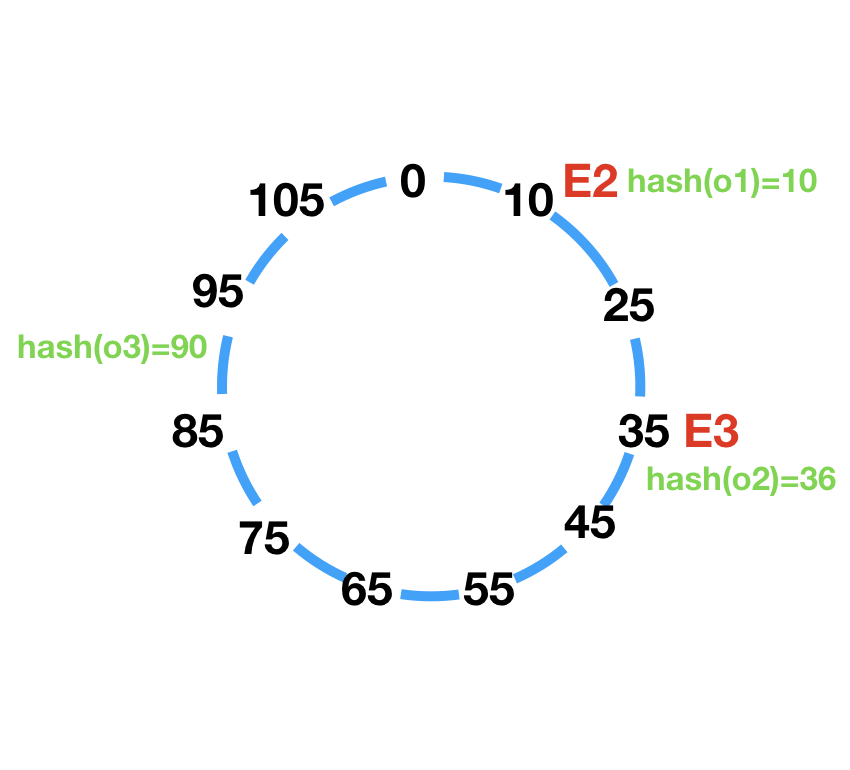
2.此时如果添加E4(hash(E4)=55),受影响的只有请求o2,从请求节点E1转移到E4:
一致性哈希可以将受影响的范围缩小为单个节点上的资源请求。
问题与优化
问题1:资源倾斜
如果哈希环很大(一般是0~2^32),并且节点hash范围很小,就会导致大部分请求落在同一个节点上,从而负载不均衡。
例如哈希环大小为10000,而节点hash范围在1000-2000之间,那么会导致90%以上的请求落在第一个节点上(hash值大于2000或者hash值小于1000)。
问题2:节点雪崩
如果环上某个节点1不可用时,那么到节点1的请求就会落入下一个节点2,导致节点2的压力增大,如果此时节点2因为压力过大而崩溃,那么所有请求会到节点3,最终的结果就会导致所有节点都不可用。
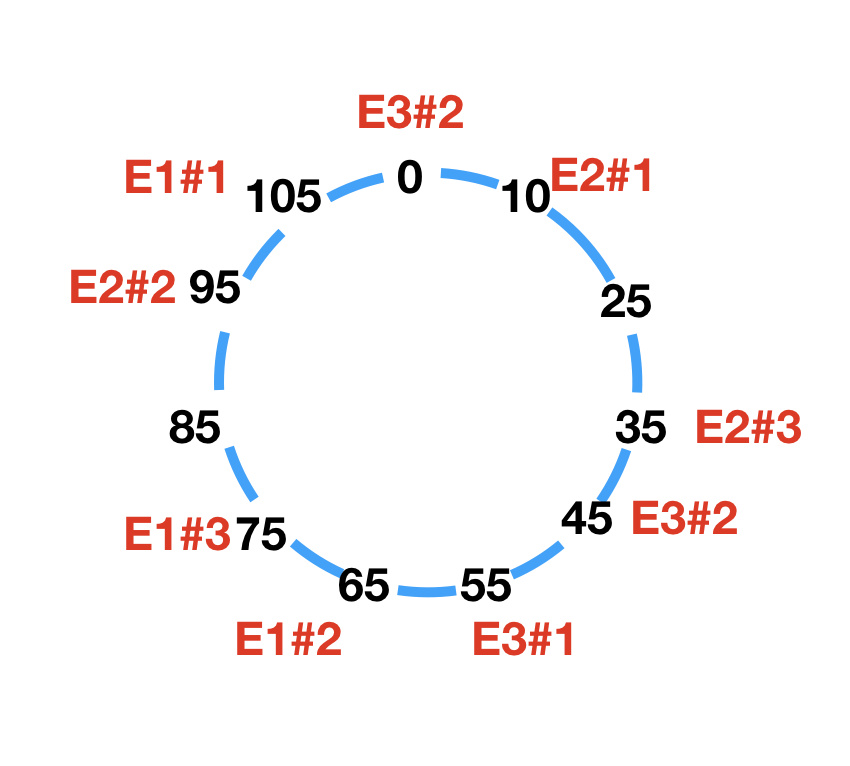
优化:引入虚拟节点
如果将一个节点拆分成多个虚拟节点,那么整个哈希环上的节点分布就会变得相对均匀,并且每个节点的资源请求也会变得相对均匀:
一致性Hash算法实现(Java)
无虚拟节点实现
1 | public class ConsistentHashingTest { |
输出结果:
1 | node:304106378. hash:192.168.1.3:11211 |
模拟1000个请求,看下请求分布情况:
1 | public static void main(String[] args) { |
输出结果相当不平均:
1 | node:192.168.1.1:11211. count:109 |
虚拟节点实现
1 | public class ConsistentHashingTest { |
输出结果比单节点均衡很多:
1 | node:192.168.1.1:11211. count:341 |