最近试了下如何通过模拟浏览器请求的方式获取网页源代码。
Selenium
Selenium 是一个用于Web应用程序测试的工具,通过调用浏览器模拟用户请求,最终获取页面源代码。好处在于可以使用浏览器 headless 模式,在无桌面环境的 linux 系统下运行。
以 Chrome 为例,安装 Chrome 后,我们需要根据浏览器版本获取到对应的浏览器驱动。
CentOS下使用
CentOS 下通过 yum 命令安装 Chrome:
1
| yum install google-chrome-stable_current_x86_64.rpm
|
该命令安装的 chrome 是最新版本,历史版本可以查看:http://orion.lcg.ufrj.br/RPMS/myrpms/google/
使用命令 google-chrome --version 查看当前安装的版本:
1
2
|
Google Chrome 101.0.4951.54
|
在官网上查找该版本对应的驱动:http://chromedriver.storage.googleapis.com/index.html ,下载并解压。
获取网页源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class Main {
public static void main(String[] args) {
String url = "https://www.163.com";
System.setProperty("webdriver.chrome.driver", "/opt/chrome/chromedriver");
ChromeOptions options = new ChromeOptions();
options.addArguments("--disable-gpu");
options.addArguments("--no-sandbox");
options.addArguments("--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36");
ChromeDriver driver = new ChromeDriver(options);
try {
driver.get(url);
String page = driver.getPageSource();
System.out.println(page);
} finally {
driver.close();
driver.quit();
}
}
}
|
运行效果:
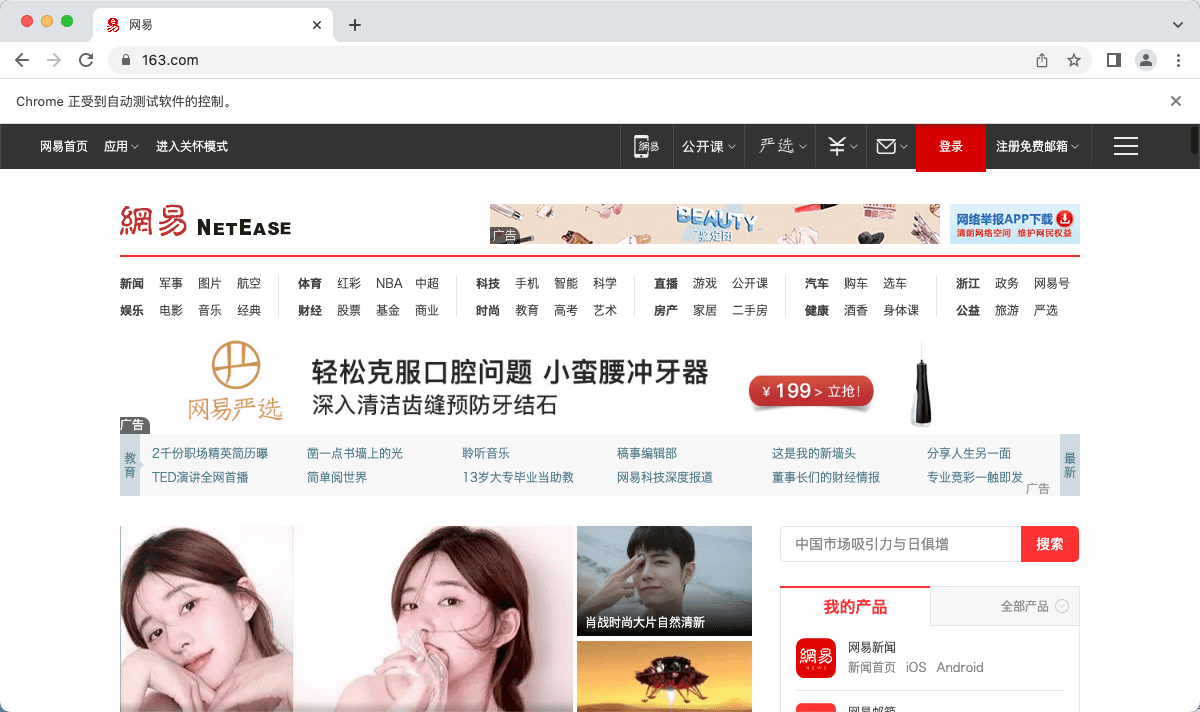
优化访问
通过设置浏览器选项禁用图片和 js:
1
2
3
4
5
6
7
8
9
10
|
options.setPageLoadStrategy(PageLoadStrategy.EAGER);
options.addArguments("--blink-settings=imagesEnabled=false");
Map<String, Object> prefs = new HashMap<>();
prefs.put("profile.managed_default_content_settings.javascript", 2);
options.setExperimentalOption("prefs", prefs);
|
运行效果:
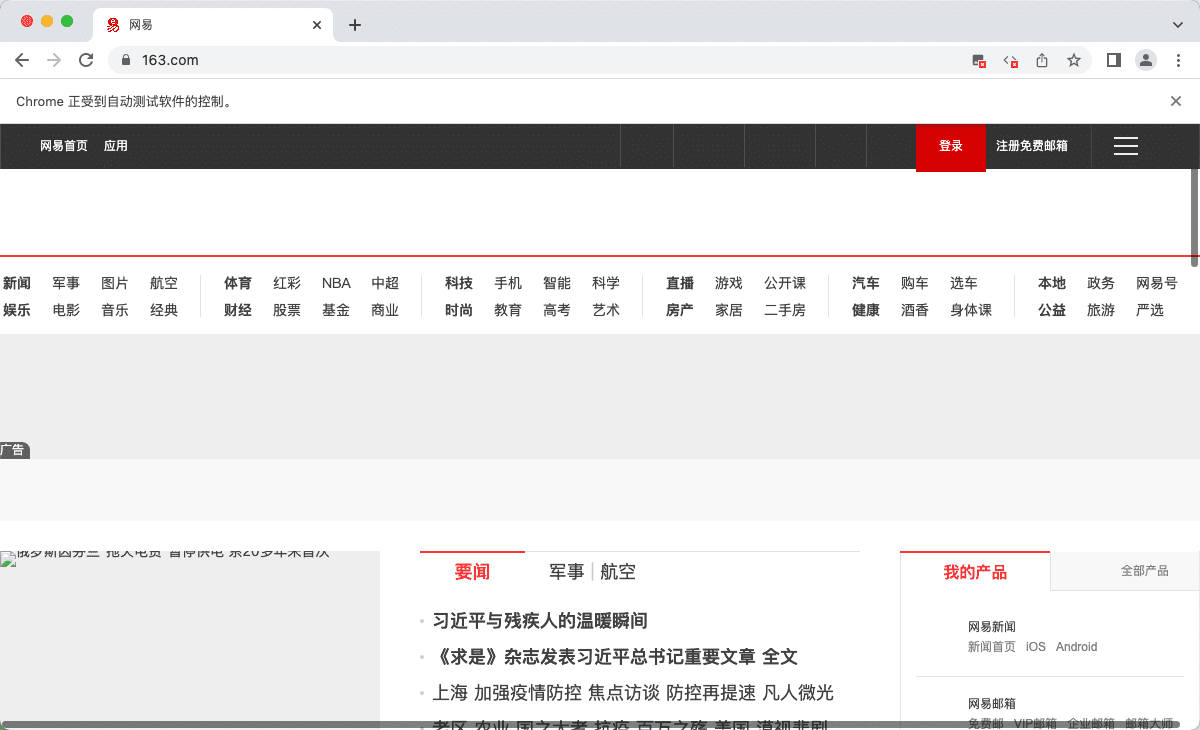
Headless
在无桌面系统的服务器上,需要启用 headless 模式:
1
| options.addArguments("--headless");
|
需要注意的是,在 headless 模式下,由于安全保护机制,很多的设置无法生效。
Webview
javaFx 中已经拥有 webview 组件,因此可以通过 webview 模拟浏览器请求,等待页面加载完成后获取网页的源代码。
一个简单的示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import javafx.application.Application;
import javafx.scene.Scene;
import javafx.scene.layout.VBox;
import javafx.scene.web.WebView;
import javafx.stage.Stage;
public class WebviewTest extends Application {
WebView webView = new WebView();
public static void main(String[] args) {
launch(args);
}
public void start(Stage primaryStage) {
String url = "https://163.com";
webView.getEngine().load(url);
VBox vBox = new VBox(webView);
Scene scene = new Scene(vBox, 1080, 600);
primaryStage.setScene(scene);
primaryStage.show();
}
}
|
运行效果:
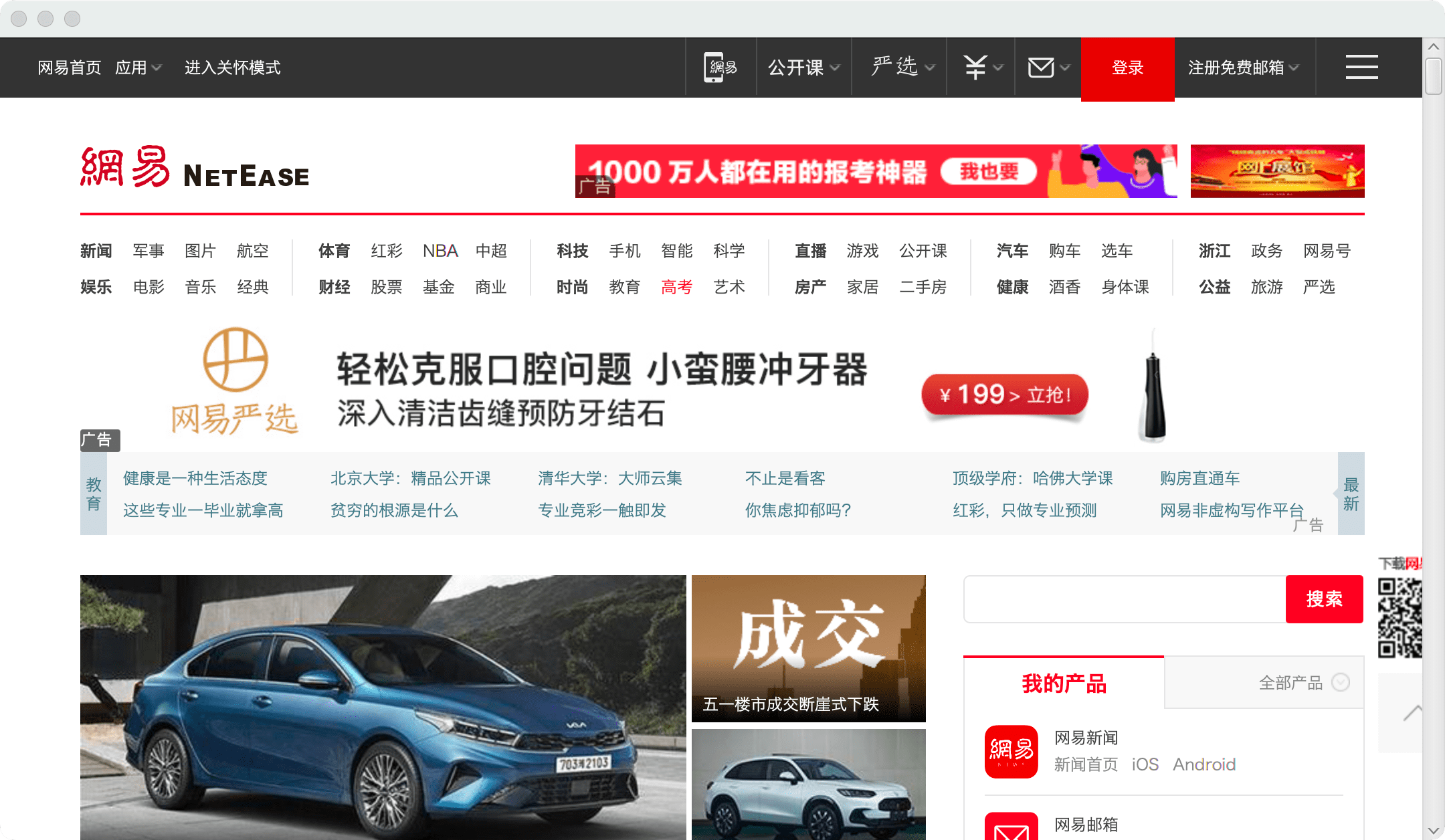
获取网页源代码
通过监听网页加载状态判断页面是否已经加载完成,加载完成后执行 javascript 脚本获取源代码:
1
2
3
4
5
6
7
8
9
|
webView.getEngine().getLoadWorker().stateProperty().addListener((observable, oldValue, newValue) -> {
if (newValue == Worker.State.SUCCEEDED) {
String html = (String) webView.getEngine().executeScript("document.documentElement.outerHTML");
System.out.println(html);
}
});
|
设置UA
1
| webView.getEngine().setUserAgent("UA");
|
优化访问
对于有些网页而言,静态资源加载(如图片等)是比较耗时的,而如果我们只想获取网页的源代码,那么类似 图片,css,js 等静态资源并不是必须的,在这种情况下,可以过滤掉部分的远程请求,加快页面的响应时间。
因为 Webview 并没有提供这样的入口,因此我们可以通过设置全局的 URLStreamHandlerFactory 实现过滤远程请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| private static void initConnection() {
URL.setURLStreamHandlerFactory(new URLStreamHandlerFactory() {
@Override
public URLStreamHandler createURLStreamHandler(String protocol) {
if ("http".equals(protocol)) {
return new sun.net.www.protocol.http.Handler() {
@Override
protected URLConnection openConnection(URL url, Proxy proxy) throws IOException {
if (ignore(url)) {
return new URL("file:local.file").openConnection();
}
return super.openConnection(url, proxy);
}
};
} else if ("https".equals(protocol)) {
return new sun.net.www.protocol.https.Handler() {
@Override
protected URLConnection openConnection(URL url, Proxy proxy) throws IOException {
if (ignore(url)) {
return new URL("file:local.file").openConnection();
}
return super.openConnection(url, proxy);
}
};
}
return null;
}
});
}
|
运行效果:
自动抓取
在程序启动后,新启线程调用 webView.getEngine().load(url) 方法,并最终提交到 javaFx 线程中执行。
1
| Platform.runLater(() -> webView.getEngine().load(url));
|
需要注意的是,需要等待上一个页面加载完成后才能继续请求下一个页面。
参考
CentOS下Chrome历史版本
Chrome驱动